This is a Machine Learning project that uses the breast cancer dataset, the objective is to predict the diagnosis by analyzing features of the tumor such as area, perimeter, radius, smoothness, compactness, concavity, symmetry, texture, among others.
The used dataset was The Breast Cancer Wisconsin, you can downloaded from the kaggle repository. Created a tool that estimates whether a tumor is malignant of benign by analyzing different features of itself. Models such as Logistic Regression, Support Vector Machines, K-Nearest Neighbors and Decision Trees obtained the best performance, with accuracy values greater than 90 % and F1-score greater than 93 %.
Features of the data
The following are the features contained in the Breast Cancer Wisconsin Dataset :
- Id
- Diagnosis
- Radius_mean
- Texture_mean
- Perimeter_mean
- Area_mean
- Smoothness_mean
- Compactness_mean
- Concave points_mean
- Symmetry_mean
- Fractal_dimension_mean
- Radius_se
- Texture_se
- Perimeter_se
- Area_se
- Smoothness_se
- Compactness_se
- Concavity_se
- Concave points_se
- Symmetry_se
- Fractal_dimension_se
- Radius_worst
- Texture_worst
- Perimeter_worst
- Area_worst
- Smoothness_worst
- Compactness_worst
- Concavity_worst
- Concave points_worst
- Symmetry_worst
- Fractal_dimension_worst 4
- Unnamed: 32
Data Cleaning
- Drop the Id and the Unnamed: 32 columns, do not provide useful information.
- Replace the categorical values of diagnosis such as (‘M’ - Malignant) and (‘B’ - Benign) to numerical values such as 0 and 1 respectively.
- Scale the values in the columns to a range of 0 to 100 in order to balance the data.
- Finally, save the processed data.
Exploratory Data Analysis (EDA)
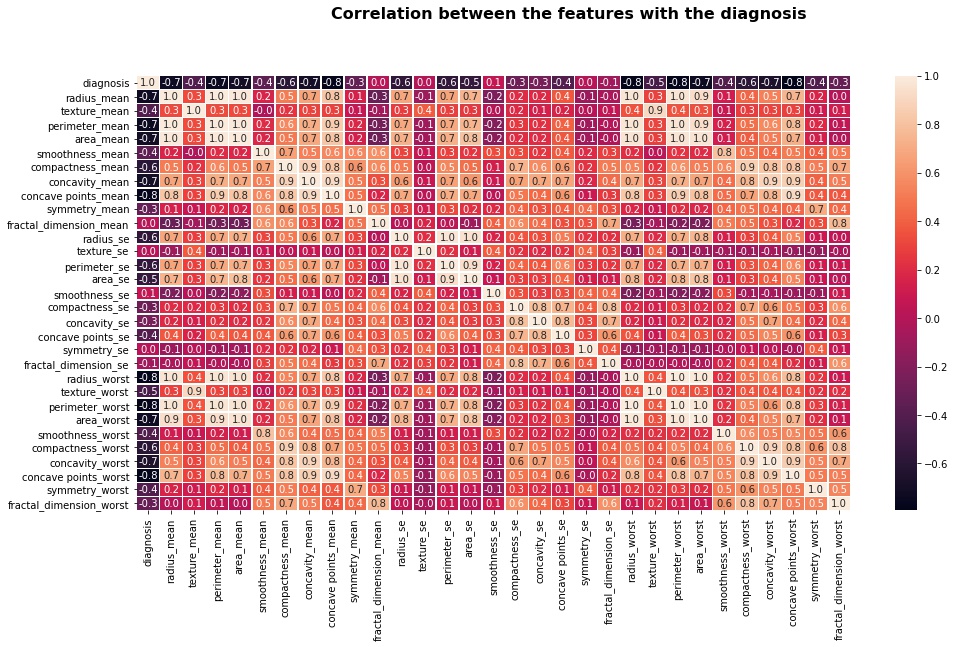
Verify the correlation between the features with the diagnosis
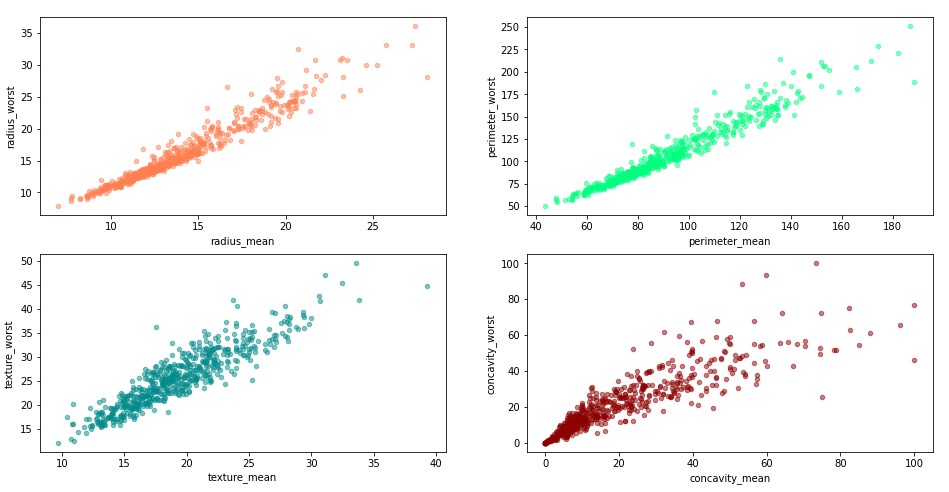
Plot scatters of different features
Model performance
The models I tried are the following :
- Logistic Regression
- Support Vector Machines
- K-Nearest Neighbors
- Decision Trees
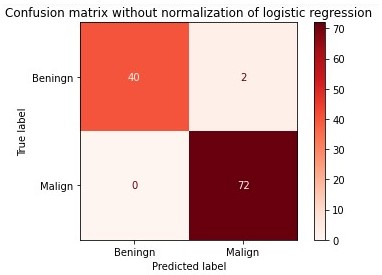
And the model with the best performance is the Logistic Regression, following the confusion matrix. As you can see, the model predicts 112 correctly instances and only 2 incorrectly instances.